Legg igjen kontaktinformasjonen din, så sender vi deg oversikten vår på e-post
Jeg samtykker til behandling av mine personopplysninger for å sende personlig tilpasset markedsmateriell i samsvar med Personvernerklæringen. Ved å bekrefte innsendingen godtar du å motta markedsmateriell.
Takk skal du ha!
Skjemaet er sendt inn. Du finner mer informasjon i innboksen din.
Innowise er et internasjonalt fullsyklus programvareutviklingsselskap grunnlagt i 2007. Vi er et team av IT-fagfolk som utvikler programvare for andre fagfolk over hele verden.
Innowise er et internasjonalt fullsyklus programvareutviklingsselskap grunnlagt i 2007. Vi er et team av IT-fagfolk som utvikler programvare for andre fagfolk over hele verden.
Kraften i datakartlegging i helsevesenet: fordeler, brukstilfeller og fremtidige trender. I takt med at helsevesenet og støtteteknologiene ekspanderer raskt, genereres det enorme mengder data og informasjon. Statistikk viser at om lag 301 Tp62T av verdens datavolum tilskrives helsevesenet, med en forventet vekst på nesten 361 Tp62T innen 2025. Dette indikerer at veksten er langt høyere enn i andre bransjer, som for eksempel produksjonsindustrien, finanssektoren og medie- og underholdningsbransjen.
Du vil bli overrasket over hvor mange selskaper som gjør dette nå.
Rapporter fra hele bransjen tyder på at det nå finnes en voksende spesialisert sektor for ingeniører som fokuserer på å korrigere AI-genererte kodefeil.
Mønsteret har blitt bemerkelsesverdig konsekvent. Bedrifter henvender seg til ChatGPT for å generere migreringsskript, integrasjoner eller hele funksjoner, i håp om å spare tid og kutte kostnader. Teknologien virker tross alt rask og tilgjengelig.
Da svikter systemene.
Og de ringer oss.
I det siste har vi fått flere og flere slike forespørsler. Ikke for å levere et nytt produkt, men for å rydde opp i rotet som ble etterlatt etter at noen stolte på en språkmodell med produksjonskoden sin.
Nå begynner det å se ut som en egen nisjebransje. Å fikse AI-genererte feil er nå en fakturerbar tjeneste. Og i noen tilfeller en svært kostbar en.
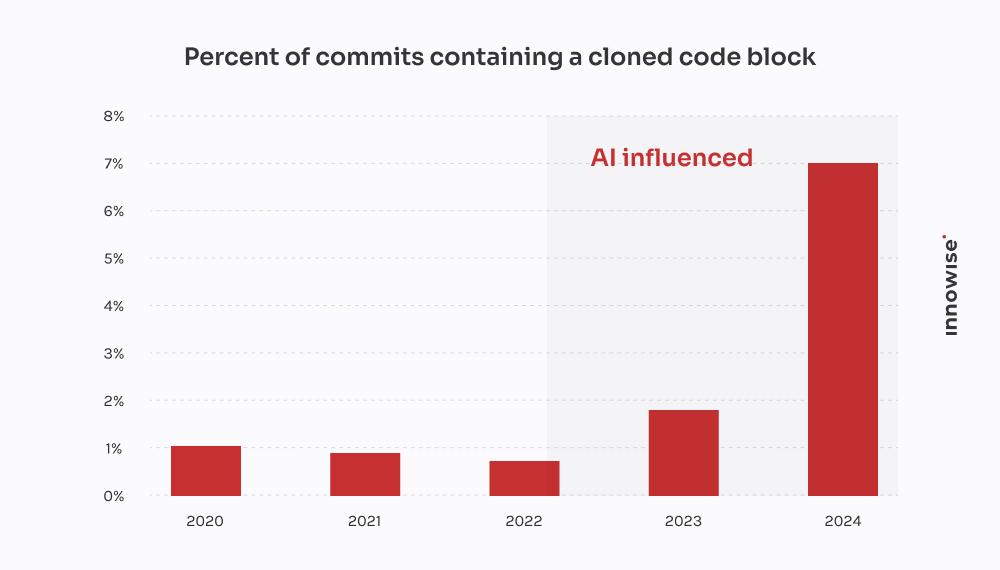
GitClears rapport for 2024 bekrefter det vi har sett hos kundene: AI-kodingsverktøyene gjør det raskere å levere, men de bidrar også til duplisering, reduserer gjenbruk og øker de langsiktige vedlikeholdskostnadene.
I ett tilfelle kom en kunde til oss etter at en AI-generert migrering hadde ført til at kritiske kundedata gikk tapt. Vi brukte30 timer med å gjenopprette det som gikk tapt, skrive om logikken fra bunnen av og rydde opp i pipelinen. Det ironiske er at det hadde vært billigere å få en seniorutvikler til å skrive det på den gammeldagse måten.
Men la det være klart: Vi er ikke “mot AI”. Vi bruker det også. Og det er nyttig i riktig sammenheng, med de rette sikkerhetsreglene. Men det som frustrerer meg – og sannsynligvis deg også – er den magiske tankegangen som ligger bak den overdrevne tiltroen til AI og dens utbredte implikasjoner. Ideen om at en språkmodell kan erstatte ekte ingeniørarbeid.
Det kan det ikke. Og som man sier, beviset ligger i puddingen. Når selskaper later som noe annet, ender de opp med å betale noen som oss for å rydde opp.
Hvordan ser en av disse oppryddingsjobbene ut? Dette er hva AI-afficionados ikke forteller deg når det gjelder tapt tid og bortkastede penger.
Slik ser en typisk forespørsel ut
Meldingen kommer vanligvis inn slik:
“Hei, kan du ta en titt på en mikrotjeneste vi har bygget? Vi brukte ChatGPT til å generere den første versjonen. Vi sendte den til staging, og nå er RabbitMQ-køen vår helt oversvømt.”
Det begynner alltid i det små. En oppgave som virker for kjedelig eller tidkrevende. Som å analysere en CSV-fil, omskrive en cron-jobb eller koble opp en enkel webhook. Så de overlater det til en språkmodell og håper på det beste.
Men her er saken: Symptomene dukker opp mye senere. Noen ganger flere dager senere. Og når de gjør det, er det sjelden åpenbart at årsaken er AI-genererte koder. Det ser bare ut som… noe er galt.
“Du kan ikke outsource arkitektonisk tenkning til en språkmodell. AI kan gjøre ting raskere, men det kreves fortsatt ingeniører for å bygge systemer som ikke faller fra hverandre under press.”
Etter et dusin av disse tilfellene begynner det å avtegne seg et mønster:
Ingen tester. I det hele tatt. Ikke engang en “hallo verden”-bekreftelse. Bare rå, spekulativ kode som aldri ble brukt skikkelig.
Ingen bevissthet om systemgrenser. Vi har sett ChatGPT-skript som spør tre mikrotjenester synkront, ignorerer tidsavbrudd og sprenger hele anropskjeden ved første feil.
Misbruk av transaksjoner. En klient brukte AI-generert SQL med nestede transaksjoner i en Node.js-tjeneste ved hjelp av Knex. Det fungerte, helt til det ikke gjorde det, og halvparten av skrivingene mislyktes i det stille.
Subtile løpsbetingelser.Spesielt i flertrådede eller asynk-tunge kodebaser. Den typen feil som ikke dukker opp under utvikling, men som ødelegger produksjonen i stor skala.
Og når alt kollapser, legger selvfølgelig ikke AI igjen en kommentar som sier: “Forresten, jeg gjetter her.”
Det er ditt ansvar.
Case 1: Migreringsskriptet som i all stillhet mistet kundedata
Denne kom fra et raskt voksende fintech-selskap.
De var i ferd med å lansere en ny versjon av kundedatamodellen sin, der ett stort JSONB-felt i Postgres ble delt opp i flere normaliserte tabeller. Ganske vanlige greier. Men med stramme tidsfrister og ikke nok hender, bestemte en av utviklerne seg for å “fremskynde ting” ved å be ChatGPT om å generere et migreringsskript.
Det så bra ut på overflaten. Skriptet parset JSON-filen, hentet ut kontaktinfo og la den inn i en ny user_contacts-tabell.
Så de kjørte det.
Ingen prøvekjøring. Ingen backup. Rett inn i staging, som viste seg å dele data med produksjonen gjennom en replika.
Noen timer senere begynte kundeservice å få e-poster. Brukere mottok ikke betalingsvarsler. Andre manglet telefonnummer i profilene sine. Det var da de ringte oss.
Hva som gikk galt
Vi sporet problemet til skriptet. Det gjorde det grunnleggende uttrekket, men det gjorde tre fatale antakelser:
It didn’t handle NULL values or missing keys inside the JSON structure.
Den satte inn delvise poster uten validering.
It used ON CONFLICT DO NOTHING, so any failed inserts were silently ignored.
Resultat: om18% av kontaktdataenevar enten tapt eller ødelagt. Ingen logger. Ingen feilmeldinger. Bare stille tap av data.
Hva som måtte til for å fikse
Vi satte ned et lite team for å rydde opp i rotet. Her er hva vi gjorde:
Diagnostisering og replikasjon (4 timer)Vi gjenskapte skriptet i et sandkassemiljø og kjørte det mot et øyeblikksbilde av databasen. Slik fikk vi bekreftet problemet og kartlagt nøyaktig hva som manglet.
Kriminalteknisk datarevisjon (8 timer)Vi sammenlignet den ødelagte tilstanden med sikkerhetskopier, identifiserte alle poster med manglende eller ufullstendige data og matchet dem mot hendelseslogger for å spore hvilke innsettinger som mislyktes og hvorfor.
Omskriving av migreringslogikken (12 timer)Vi skrev om hele skriptet i Python, la til full valideringslogikk, bygget en tilbakeføringsmekanisme og integrerte det i kundens CI-pipeline. Denne gangen inkluderte det tester og støtte for tørrkjøring.
Manuell gjenoppretting av data (6 timer) Noen poster kunne ikke gjenopprettes fra sikkerhetskopier. Vi hentet manglende felt fra eksterne systemer (CRM- og e-postleverandør-API-er) og gjenopprettet resten manuelt.
Total tid: 30 ingeniørtimer
To ingeniører, tre dager. Kostnad for kunden: ca.$4,500i serviceavgifter.
Men det største tapet kom fra kundene. Manglende varslinger førte til tapte betalinger og kundefrafall. Kunden fortalte oss at de brukte minst$10,000på supporthenvendelser, SLA-kompensasjon og goodwill-kreditter på grunn av det ene feilslåtte skriptet.
Det ironiske er at en seniorutvikler kunne ha skrevet den riktige migreringen på kanskje fire timer. Men løftet om AI-hastighet endte opp med å koste dem to uker med opprydding og skade på omdømmet.
Vi fikser det ChatGPT ødela - og bygger det den ikke kunne.
Case 2: API-klienter som ignorerte hastighetsbegrensninger og ødela produksjonen
Denne kom fra en oppstartsbedrift innen juridisk teknologi som bygger en dokumenthåndteringsplattform for advokatfirmaer. En av kjernefunksjonene deres var å integrere med en statlig e-varslingstjeneste – et tredjeparts REST API med OAuth 2.0 og streng hastighetsbegrensning: 50 forespørsler per minutt, uten unntak.
I stedet for å tildele integrasjonen til en erfaren backend-utvikler, bestemte noen på teamet seg for å “prototype den” ved hjelp av ChatGPT. De la inn OpenAPI-spesifikasjonen, ba om en Python-klient, og fikk et rent utseende skript med requests, retry-logikk (prøv på nytt) ved hjelp av tenacity, og token-oppdatering.
Så solid ut på papiret. Så de sendte det.
Hva som gikk galt
Til å begynne med virket alt bra. Klienten håndterte individuelle forespørsler korrekt, godkjente autentisering og prøvde til og med på nytt ved feil. Men under reell bruk, spesielt under belastning, begynte plattformen å oppføre seg uforutsigbart.
Her er hva som faktisk skjedde:
Ingen respekt for takstgrenser. The generated code didn’t read or interpret X-RateLimit-Remaining or Retry-After headers. It just kept sending requests blindly.
Nye forsøk gjorde ting verre.Da 429-feilene begynte å komme tilbake, prøvde tenacity-dekoratoren dem automatisk på nytt. Ingen jitter. Ingen kø. Bare en flom av oppfølgingsforespørsler.
API-leverandøren blokkerte IP-en deres midlertidig.I tre timer kunne ingen på plattformen synkronisere dokumenter. Ingen logger, ingen varsler. Bare en stille feil.
This wasn’t a one-line fix. It was a misunderstanding of how production systems behave. And it’s a great example of what LLMs don’t know; not because they’re broken, but because they don’t have runtime awareness.
Slutt å lappe AI-generert kode i prod - ta oss med før den går i stykker.
Spore og isolere feilen (6 timer)Vi la til mellomvare for å inspisere utgående trafikk og fikk bekreftet flommen av forespørsler under toppbelastning. Vi gjenskapte også feilen i staging for å forstå det utløsende mønsteret fullt ut.
Gjenoppbygge API-klienten (10 timer) We rewrote the client using httpx.AsyncClient, implemented a semaphore-based throttle, added exponential backoff with jitter, and properly handled Retry-After and rate-limit headers.
Stresstest og validering (6 timer)Vi simulerte virkelig bruk med tusenvis av samtidige forespørsler ved hjelp av Locust, testet hastighetsbegrensning under ulike burst-scenarioer og bekreftet null 429s under vedvarende belastning.
Legg til overvåking og varsling (4 timer)Vi satte opp egendefinerte Prometheus-beregninger for å spore API-bruk per minutt, og la til varsler for å varsle teamet hvis de nærmet seg terskelverdiene.
Total tid: 26 timer
To ingeniører, fordelt på to og en halv dag. Kostnad for kunden: ca.$3,900.
Det største problemet var at deres største kunde – et advokatfirma med tidssensitive innleveringer – gikk glipp av to innsendingsvinduer på grunn av strømbruddet. Kunden måtte begrense skaden og tilby en rabatt for å beholde kontoen.
Alt fordi en språkmodell ikke forsto forskjellen mellom “fungerende kode” og “produksjonsklar kode”. Og akkurat slik ble enda et lag med teknisk gjeld fra AI i stillhet lagt til i stakken.
Hvorfor dette fortsetter å skje
Det skremmende er ikke at disse tingene går galt. Det er hvor forutsigbart det begynner å bli.
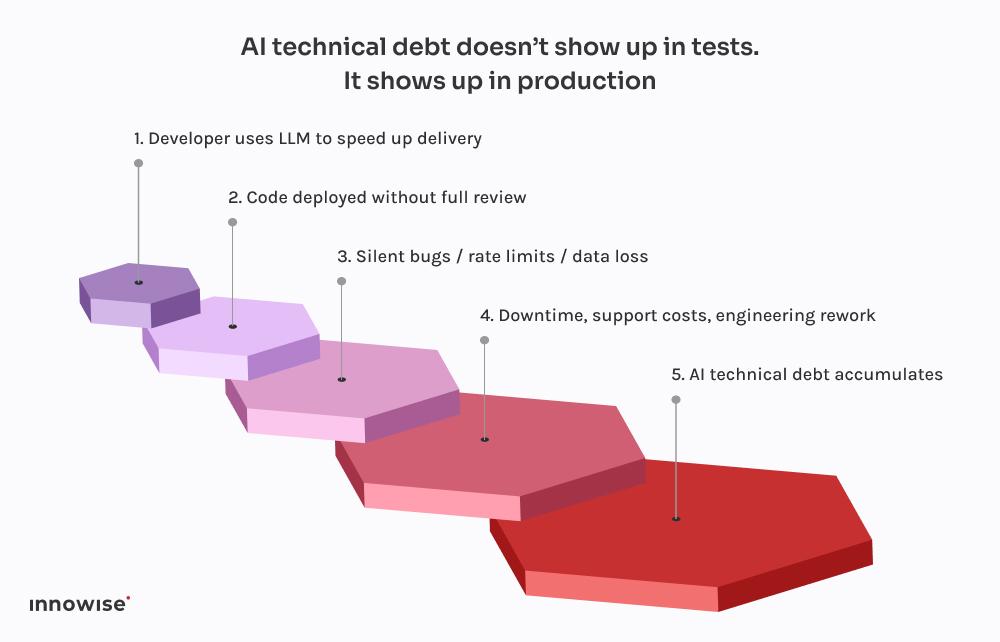
Alle disse hendelsene følger det samme mønsteret. En utvikler ber ChatGPT om en kodesnutt. Den returnerer noe som fungerer akkurat godt nok til ikke å gi feil. De kobler det inn i systemet, rydder kanskje litt opp i det, og sender det ut i den tro at hvis det kompilerer og kjører, må det være trygt.
Men her er haken: Store språkmodeller kjenner ikke systemet ditt. De vet ikke hvordan tjenestene dine samhandler. De kjenner ikke latensbudsjettet ditt, distribusjonspipelinen din, observasjonsoppsettet ditt eller trafikkmønstrene dine i produksjonen.
De genererer den koden som ser mest sannsynlig ut, basert på mønstre i opplæringsdataene. Det er alt. Det er ingen bevissthet. Ingen garantier. Ingen intuisjon for systemdesign.
Og det gjenspeiler seg ofte i resultatet:
Kode som fungerer én gang, men som feiler under belastning
Ingen defensiv programmering, ingen feilsikringer
Dårlig forståelse av begrensninger i den virkelige verden, som f.eks. hastighetsbegrensninger, tidsavbrudd eller eventuell konsistens
Absolutt null sans for arkitektonisk intensjon
Det verste er at koden ser korrekt ut. Den er syntaktisk ren. Den passerer linters. Den kan til og med være dekket av en grunnleggende test. Men den mangler det eneste som faktisk betyr noe: kontekst.
Det er derfor disse feilene ikke dukker opp med en gang. De venter på utrullinger fredag kveld, på perioder med høy trafikk, på sjeldne unntakstilfeller (edge cases). Det er naturen til teknisk gjeld fra AI – den er usynlig frem til den ødelegger noe kritisk.
Når AI faktisk hjelper
Som vi nevnte tidligere, bruker vi også AI. Så godt som alle ingeniørene i teamet vårt har et Copilot-lignende oppsett som kjører lokalt. Det er raskt, nyttig og ærlig talt en flott måte å hoppe over de kjedelige delene på.
Men her er forskjellen: Ingenting kommer inn i hovedgrenen uten å gå gjennom en senioringeniør, og i de fleste tilfeller en CI-pipeline som vet hva den skal se etter.
LLM-er er gode til:
stillasbygging for nye tjenester eller API-endepunkter,
generere testdekning for eksisterende logikk,
hjelper til med repeterende refaktorisering på tvers av store kodebaser,
oversetter enkle skallskript til infrastruktur-som-kode-maler,
eller til og med sammenligne algoritmiske tilnærminger vi allerede forstår.
Hva de erikkeer god på er design. Eller kontekst. Eller trygge standardinnstillinger.
Derfor har vi bygget opp arbeidsflytene våre slik at de behandler LLM-resultatene som forslag, ikke som en sannhetskilde. Slik ser det ut i praksis:
Vi tagger alle AI-genererte kommitteringer slik at de er enkle å spore og gjennomgå.
Redaktørene våre har innebygde ledetekster, men med påtvungne pre-commit-kroker som blokkerer alt uten tester eller dokumentasjon.
Vår CI inneholder regler for statisk analyse som flagger usikre mønstre vi har sett før fra LLM-er: ting som ubeskyttede gjentakelser, tidsavbrudd uten omfang, naiv JSON-parsing eller usikker SQL-håndtering.
Alle pull-forespørsler med LLM-generert kode går gjennom en obligatorisk menneskelig gjennomgang, vanligvis av en overordnet som forstår domenelogikken og risikooverflaten.
Brukt riktig er det tidsbesparende. Brukt i blinde er det en tidsinnstilt bombe.
Hva vi anbefaler til CTO-er
Vi er ikke her for å be deg om å forby AI-verktøy. Det skipet har seilt.
Men å gi en språkmodell commit-tilgang? Det er bare å be om problemer.
Her er hva vi anbefaler i stedet:
1. Behandle LLM-er som verktøy, ikke som ingeniører
La dem hjelpe til med repeterende kode. La dem foreslå løsninger. Menikke overlate kritiske beslutninger til dem. All kode som genereres av AI, skal gjennomgås av en senioringeniør, uten unntak.
2. Gjør LLM-generert kode sporbar
Enten det er commit-tagger, metadata eller kommentarer i koden,gjør det tydelig hvilke deler som kommer fra AI. Det gjør det enklere å revidere, feilsøke og forstå risikoprofilen i ettertid.
3. Definere en generasjonspolicy
Bestem i fellesskap hvor det er akseptabelt å bruke LLM-er, og hvor det ikke er det. Boilerplate? Ja visst. Autentiseringsflyt? Kanskje. Transaksjonssystemer? Absolutt ikke uten gjennomgang.Gjør retningslinjene eksplisitteog en del av dine tekniske standarder.
4. Legg til overvåking på DevOps-nivå
Hvis du lar AI-generert kode komme i kontakt med produksjon, må du anta at noe til slutt vil gå i stykker. Legg til syntetiske kontroller. Overvåk hastighetsbegrensninger. Avhengighetssporing.Gjør det usynlige synlig, spesielt når den opprinnelige forfatteren ikke er et menneske.
5. Bygg for gjenopprettbarhet
De største AI-drevne feilene vi har sett, kom ikke fra “dårlig” kode. De kom av stille feil – manglende data, ødelagte køer, stormer av nye forsøk – som ikke ble oppdaget på flere timer.Invester i observerbarhet, reservelogikk og tilbakeføringer.Spesielt hvis du lar ChatGPT skrive migreringer.
Kort sagt kan AI spare teamet ditt for tid, men den kan ikke ta ansvar.
Det er fortsatt en menneskelig jobb.
Avsluttende tanker: AI ≠ programvareingeniører
AI kan hjelpe deg med å bevege deg raskere. Men den kan ikke tenke for deg.
Den forstår ikke arkitekturen din. Den vet ikke hva “ferdig” betyr i din kontekst. Og den bryr seg definitivt ikke om datapipelinen din går i stykker en fredag kveld.
Derfor må vi som teknologidirektører fokusere på systemets robusthet, ikke bare på hastighet.
Det er fristende å la AI ta seg av de kjedelige delene. Og noen ganger er det helt greit. Men alle snarveier kommer med en ulempe. Når AI-generert kode slipper gjennom uten å bli kontrollert, blir den ofte til AI-teknisk gjeld. Den typen du ikke ser før driftsteamet ditt er i gang med brannslukking i produksjonen.
Hvis du allerede har møtt veggen, er du ikke alene. Vi har hjulpet team med å komme seg etter alt fra ødelagte migreringer til API-katastrofer. Vi refaktoriserer ikke bare kode. Vi hjelper med å refaktorere tankegangen bak den.
For til syvende og sist er det det som gjør systemene pålitelige.
Philip har et skarpt fokus på alt som har med data og AI å gjøre. Han er den som stiller de riktige spørsmålene tidlig, setter en sterk teknisk visjon og sørger for at vi ikke bare bygger smarte systemer – vi bygger de riktige, for å skape reell forretningsverdi.
Et dypdykk i rollen som Frontier Deployment Engineer og hvordan FDE-er forvandler eksperimentelle AI-piloter til sikre, målbare og skalerbare AI-produksjonssystemer.
 Lei oss
Lei oss